When the Orchestrator Isn't Code⌗
A treatise on agents that act
Prelude⌗
1/ A wrong sentence is forgiven. A wrong charge is disputed. A wrong message — sent under your name, to your customer, on your authority — is apologised for, sometimes for years. The cost of being wrong about words and the cost of being wrong about acts are not on the same scale. The systems that produce them must not be either.
2/ A chatbot produces words. An agent produces acts. The chatbot's failures stay inside the conversation. The agent's failures leak into the world.
3/ This is not a degree of difference. It is a difference of kind. A model that places trades, sends messages, books trips, files tickets, signs documents — that model is not a chatbot with extra steps. It is a different category of system, and the category has its own engineering.
4/ Most current agent frameworks have not yet admitted this. They treat the agent as a chatbot with hands. Tools are added. Retries are wrapped. State is checkpointed. The pattern of the chatbot is preserved while the consequences underneath it have changed. The retry decorator is the tell.
5/ Every retry decorator is a place where the framework asked the developer to solve, by hand, what ledgers and merchants and clearing houses solved at the boundary a long time ago. Multiplied across every tool call, the developer rebuilds — badly — the workflow runtime they did not realise they needed.
6/ The reasonable objection. Merchants already keep books. Stripe deduplicates. Shopify holds carts. Brokers accept idempotency keys. Why does the agent need to keep books above the merchant?
7/ Because each merchant keeps the half of the ledger that protects the merchant. None keeps the half that protects the agent. After a restart, an agent without its own books cannot tell whether the call was made and the response was lost, or never made at all. Two systems, both correct, neither wrong, and reality somewhere between them until someone reconciles.
8/ This is the floor. It is well-trodden. Lamport in 1978: there is no global clock. Garcia-Molina and Salem in 1987: maintain consistency through compensation. Helland later: distributed systems live on grants, agreements, and apologies. Forty years of literature has been telling agent builders what they are about to discover.
9/ The ceiling is new. The forward path of an LLM-orchestrated agent is not a graph an engineer can enumerate at design time. The compensation depends on what the model decided. The action space is open. The audit, when it comes — and it will come — must include reasoning, not effects alone. The journal stops being a record of what happened. It becomes the record of why.
10/ Frameworks have noticed. Temporal, Restate, DBOS, Step Functions, Cloudflare Workflows. The runtime layer is being built. The agent framework layer is, increasingly, an application of it.
11/ The deflationary argument — we already have sagas — is correct about the floor and silent about the ceiling. The expansive argument — agents need everything new — is wrong about the floor and right about the ceiling. The conversation goes in circles because the language has not separated the two.
12/ The chatbot was forgiven for forgetting. The agent will not be. An agent is a contract with the world. The runtime is what keeps the contract honest.
I. The Asymmetry⌗
1/ An agent is a chatbot that can spend your money. That is the whole story and the whole problem.
2/ Look at it from the system's side, not the user's. A chatbot returns text. The text is consumed by the user, who decides whether to act on it. The user is the integration point. The user catches errors. The user reconciles. The user is, in the language of distributed systems, the end-to-end check.
3/ An agent removes the user from that role. The agent is the integration point. The agent catches errors. The agent reconciles. The agent is the end-to-end check. The user has delegated the role and gone to bed.
4/ This is the move. The user has handed the agent authority to commit on their behalf. Commit is not a metaphor. It is the database word. It is the point at which a change becomes durable, becomes other people's truth, becomes something that can no longer be unsaid by deciding not to mean it.
5/ The chatbot does not commit. The chatbot proposes. The agent commits.
6/ A system that proposes is graded on the proposal. A system that commits is graded on whether the commitment was correct, whether it was authorised, whether it was honoured by the counterparty, whether the counterparty's record agrees with the agent's record, and whether anyone, asked, can reconstruct what happened.
7/ Five graders, not one. None of them are reading the prose.
8/ This is why the discipline becomes less a 2020s machine-learning problem than a 1990s distributed-systems problem with a stochastic step in the middle. The hard part is not the model. The hard part is the part of the system that must keep promises across crashes, deploys, network partitions, and the model's own caprice.
9/ The model has been improving for ten years. The system around it has not. Every benchmark gain in reasoning, every new tool-use capability, every longer context window is a benchmark gain at the front of the contract. The back of the contract has not moved.
10/ The chatbot was forgiven for forgetting. The agent will not be.

II. Three Commitments⌗
Three concrete cases. The first two as prose, briefly, to establish the shape. The third in detail — diagrams, code, and the ceremony the developer ends up writing — because the third is where the argument stops being an argument and becomes a bill of work.
The shopping agent⌗
1/ A user says: find me these running shoes in size 11, ship to my home.
2/ The request resolves into four commitments across three systems. The cart held at the retailer. The payment authorised on the card. The order committed at the retailer. Inventory decremented in a real warehouse three states away.
3/ Four promises. Three vendors. None of them know about each other.
4/ The agent's process dies between the second commitment and the third. The card has a hold. The order does not exist. The user does not know.
5/ Without durable execution, the agent on retry runs from the top. Searches again. Picks again. Attempts checkout again. Whether duplicates fire at the retailer or at the card depends on whose idempotency layer is paying attention. The optimistic outcome is one charge, one order. The pessimistic outcome is two charges, one order, and an angry email at nine in the morning.
6/ The merchant's idempotency layer was already there. Stripe's twenty-four-hour key cache. Shopify's cart tokens. The airline's PNR. None of them were built for agents. They were built for humans submitting forms twice when the page did not load.
7/ Agents do not need new plumbing. They need to plug into old plumbing correctly. The patterns that survived a decade of microservice failure are the patterns agents need.
8/ A shopping agent is four promises in a row, each to a different system. Two charges and one shipment is worse than no shipment at all.

The travel agent⌗
1/ Travel is shopping with a longer time horizon and more vendors. It gets harder along both axes.
2/ A round trip to Singapore. Outbound flight, return flight, hotel, sometimes a car, a payment processor. Five external systems. None know about each other. None agree on what time it is.
3/ The interesting failure is the partial commit. Outbound booked. Return rejected because the fare class disappeared in the fifteen seconds since the search.
4/ Now the user has half a trip and a charge. Three responses are available. Cancel the outbound and refund — compensation. Retry the return at the next available fare — forward recovery. Surface the failure and wait — escalation.
5/ Each is a real saga path. None of them are reachable without a runtime that remembers what was committed and what was not.
6/ Time adds a second axis. Travel approvals come from partners, expense systems, managers. The agent presents an itinerary and waits. The wait may be ten minutes or two days.
7/ During that wait, the process holding agent state cannot stay pinned in memory. The operator deploys. The host autoscales. The cluster reschedules. The user clicks approve, and nothing happens, because nothing on the other side is listening anymore.
8/ The hard part of travel is not booking. It is unbooking. Any travel agent that can commit but cannot roll back is a travel agent that should not be authorised to commit.

The treasury agent — a walk through one day⌗
The third case is the one with the highest cost of getting wrong, and it is worth walking through in full because the walk reveals what the developer ends up writing when the framework declines to.
The scenario⌗
1/ The CFO writes the standing policy each morning. How much cash sits in each operating account. Where the excess sweeps to. Which counterparties are allowed. What FX exposures are tolerable, and at what notional. What amounts cross the line into ask me first. The policy is short. The policy is binding. The policy is what the regulator will compare against, line by line, when something goes wrong.
2/ The market closes. The agent runs. Across four banks in three currencies, it reads balances and the day's flows. It pulls rates from the data vendor. It applies the policy to the day's facts. The excess in USD operating goes to the whitelisted money-market fund. The AUD short above threshold is hedged on the agreed forward. Intercompany funding is instructed. GL entries are posted. The liquidity ratio is filed with the regulator. A summary lands on the CFO's phone before dinner.
3/ This is one run. It will run every business day. It must not over-sweep, double-hedge, miss a cutoff, or post the same entry twice. It must not pay the wrong counterparty by a digit. It must not file a ratio computed on stale balances. When it does any of these — and it will, once — the treasurer will be asked, by someone who is not in a forgiving mood, what the agent did and why.
4/ The chatbot was forgiven for forgetting. The treasury agent will not be. The agent's day is a contract with the firm, the bank, the counterparty, and the regulator, all of whom keep books, none of whom keep the agent's books for it.
The ceremony, in seven points⌗
The work each tool call has to do, every time, regardless of which framework it lives in:
① The instruction is sent twice; the money moves once. The idempotency key is the agent's promise to the bank. The developer derives it by hand from (run_date, account_id, amount_minor, target) and prays the inputs are stable across retries.
② Check the journal before acting. If the prior attempt confirmed, return its result. The check exists because the act is not free, not undoable, and not always knowable from the bank alone.
③ The intent is written before the wire leaves. A crash between the write and the wire leaves a trace. A crash between the wire and the ack leaves a question. Without the pre-write, both are silence — and silence at the close is the worst state a treasury can be in.
④ The act. The framework treats it as a function call. The world treats it as money moved. The two treatments must be reconciled, and reconciliation is the developer's job until the runtime takes it.
⑤ The outcome is written when it returns. Confirmed, failed, or unknown. The unknown is not a developer error. It is a category of state the journal must hold, because the network can lose acks, the bank can be slow, and the cutoff is at four o'clock regardless.
⑥ Compensation registered with the act. The reversing entry for a misposted GL line. The cancelling instruction for a wire still in the queue. The offsetting hedge for an over-hedge. The agent that does not journal compensation handles cannot apologise to the world in time.
⑦ The reasoning is journaled with the action, not after it. Why this counterparty. Why this amount. Why this minute. The CFO will ask. The auditor will ask. The regulator, when it comes, will ask in writing and expect the answer in writing. The journal that records what without why is the journal of a chatbot, not an agent.
5/ Seven points. Six of them rebuild what ledgers and clearing houses solved at the boundary forty years ago. The seventh is the new ceiling — and none of the frameworks below give the developer a place to put it that survives the run.
LangGraph⌗
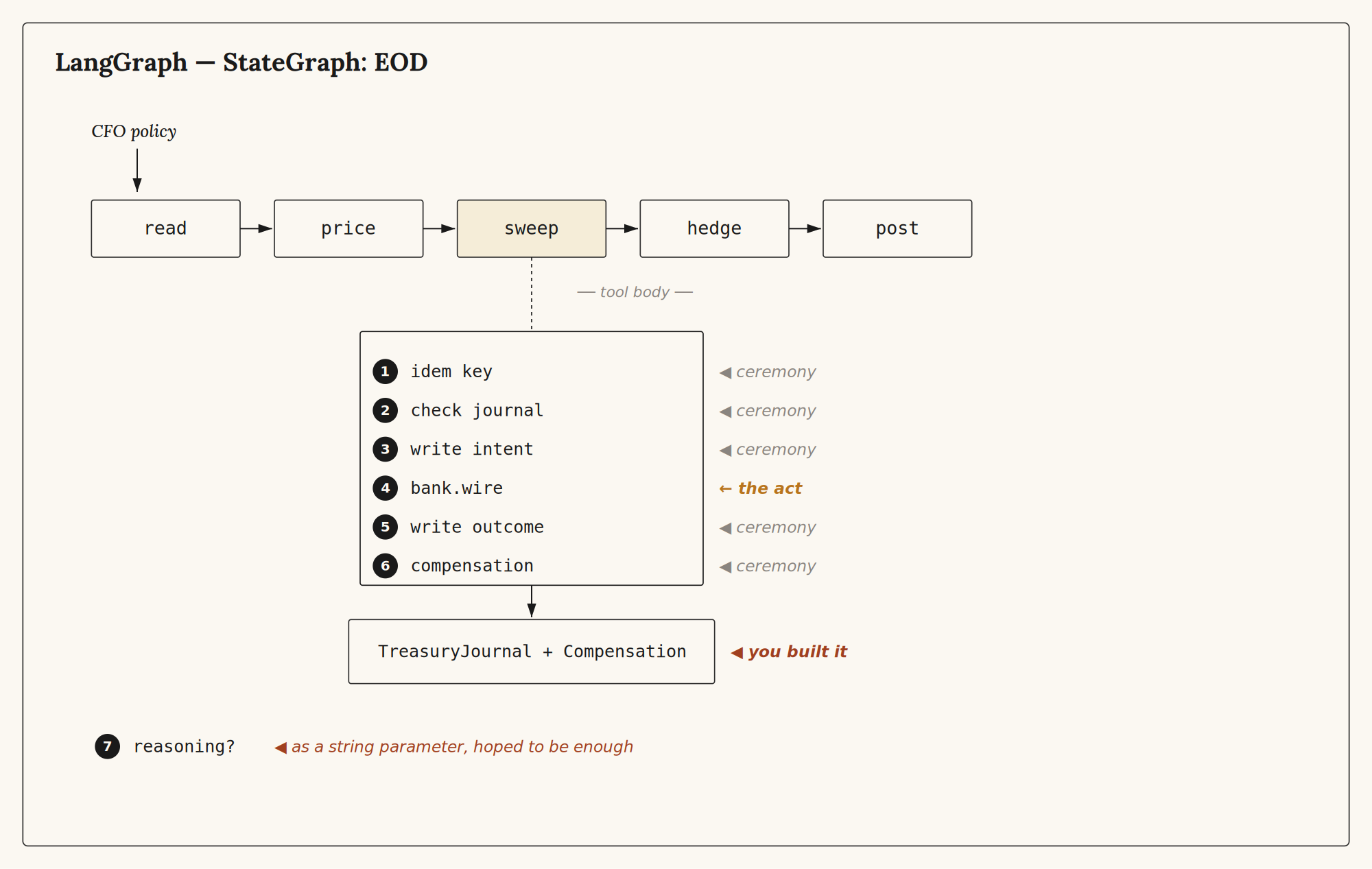
from langgraph.graph import StateGraph, END
from tenacity import retry, stop_after_attempt, wait_exponential
import hashlib
@retry(stop=stop_after_attempt(3), wait=wait_exponential())
def execute_sweep(state: TreasuryState) -> TreasuryState:
# ① idempotency — derived from inputs we hope are stable across retries
key = hashlib.sha256(
f"{state['run_date']}:{state['account_id']}:"
f"{state['amount_minor']}:{state['target_mmf']}".encode()
).hexdigest()
with Session(engine) as s:
# ② check the journal we built
prior = s.query(TreasuryJournal).filter_by(key=key).first()
if prior and prior.status == "confirmed":
return {**state, "wire_id": prior.wire_id}
# ③ write intent before the wire leaves
s.add(TreasuryJournal(
key=key, status="pending",
account_id=state["account_id"],
amount_minor=state["amount_minor"],
target=state["target_mmf"],
rationale=state["rationale"], # ⑦ the model's why, as a string
))
s.commit()
# ④ the act
try:
wire_id = bank.wire(
account=state["account_id"],
amount_minor=state["amount_minor"],
target=state["target_mmf"],
idempotency_key=key,
)
except UnknownAck:
# ⑤ the third status — neither confirmed nor failed
with Session(engine) as s:
s.query(TreasuryJournal).filter_by(key=key).update({"status": "unknown"})
s.commit()
raise # reconciliation will resolve this later
except Exception:
with Session(engine) as s:
s.query(TreasuryJournal).filter_by(key=key).update({"status": "failed"})
s.commit()
raise
with Session(engine) as s:
# ⑤ write outcome
s.query(TreasuryJournal).filter_by(key=key).update(
{"status": "confirmed", "wire_id": wire_id}
)
# ⑥ register the compensation handle — what unwinds this if hedge fails
s.add(Compensation(
key=key, kind="reverse_wire",
payload={"wire_id": wire_id, "account": state["account_id"]},
))
s.commit()
return {**state, "wire_id": wire_id}
graph = StateGraph(TreasuryState)
graph.add_node("read", read_balances)
graph.add_node("price", price_market)
graph.add_node("sweep", execute_sweep)
graph.add_node("hedge", execute_hedge) # same ceremony, repeated
graph.add_node("post", post_gl) # same ceremony, repeated
graph.add_edge("read", "price"); graph.add_edge("price", "sweep")
graph.add_edge("sweep", "hedge"); graph.add_edge("hedge", "post")
graph.add_edge("post", END)
6/ The graph is the agent. The journal is the runtime the graph declined to be.
ADK⌗
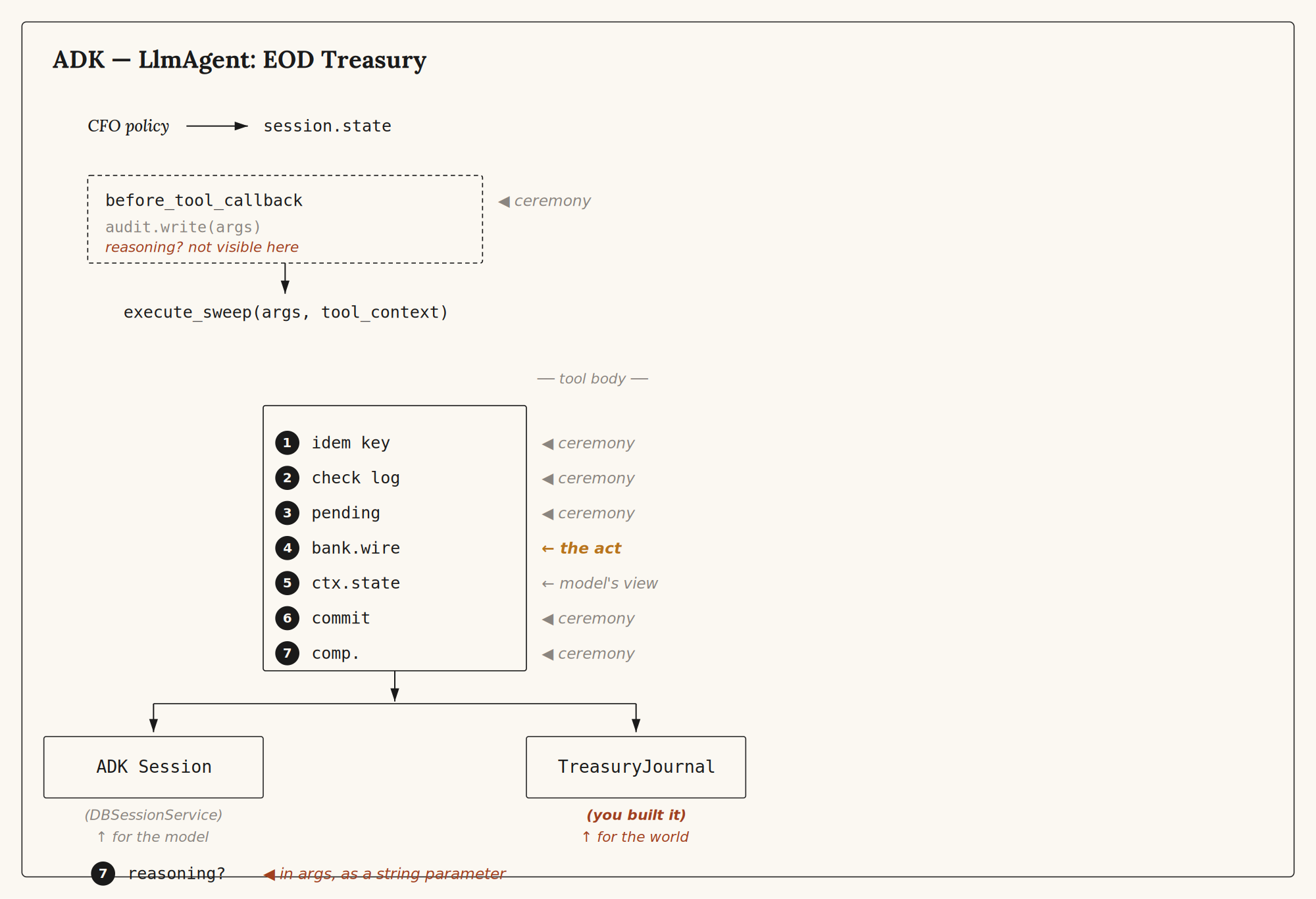
from google.adk.agents import LlmAgent
from google.adk.tools import FunctionTool
from google.adk.sessions import DatabaseSessionService
session_service = DatabaseSessionService(db_url="postgresql://...")
def execute_sweep(
account_id: str,
currency: str,
amount_minor: int,
target_mmf: str,
run_date: str,
rationale: str, # ⑦ the model's why, as best we can capture
tool_context,
) -> dict:
# ① idempotency key — invocation_id helps when inputs would otherwise repeat
key = hashlib.sha256(
f"{run_date}:{account_id}:{amount_minor}:{target_mmf}".encode()
).hexdigest()
with side_journal() as j:
# ② check the journal we built alongside the session
if j.exists(key, status="confirmed"):
return {"wire_id": j.wire_id(key)}
# ③ write intent
j.write(key, status="pending",
account_id=account_id, amount_minor=amount_minor,
target=target_mmf, rationale=rationale)
# ④ the act
try:
wire_id = bank.wire(account_id, amount_minor, target_mmf, idempotency_key=key)
except UnknownAck:
with side_journal() as j: j.write(key, status="unknown")
raise
except Exception:
with side_journal() as j: j.write(key, status="failed")
raise
# ⑤ session.state — what the model will read next turn
tool_context.state[f"sweep:{account_id}:{run_date}"] = wire_id
# ⑥ our journal — what survives the model
with side_journal() as j: j.write(key, status="confirmed", wire_id=wire_id)
# ⑦ compensation handle
with comp_journal() as c:
c.register(key, kind="reverse_wire",
payload={"wire_id": wire_id, "account": account_id})
return {"wire_id": wire_id}
def before_tool_callback(tool, args, tool_context):
# audit fires on the call. the deliberation that produced `args` and
# `rationale` is upstream of this hook; we get the result, not the reasoning.
audit.write({
"invocation": tool_context.invocation_id,
"tool": tool.name,
"args": redact(args),
"policy_version": tool_context.state.get("cfo_policy_version"),
})
agent = LlmAgent(
model="gemini-2.5-pro",
instruction="Apply the CFO policy in session.state to today's positions.",
tools=[FunctionTool(execute_sweep), FunctionTool(execute_hedge), FunctionTool(post_gl)],
before_tool_callback=before_tool_callback,
)
7/ ADK splits the ceremony across three places — callback, tool body, session state — and the developer keeps all three in step. The session is durable. The session is the wrong shape for a ledger. Two ledgers, one process, one team paying for the gap.
CrewAI⌗
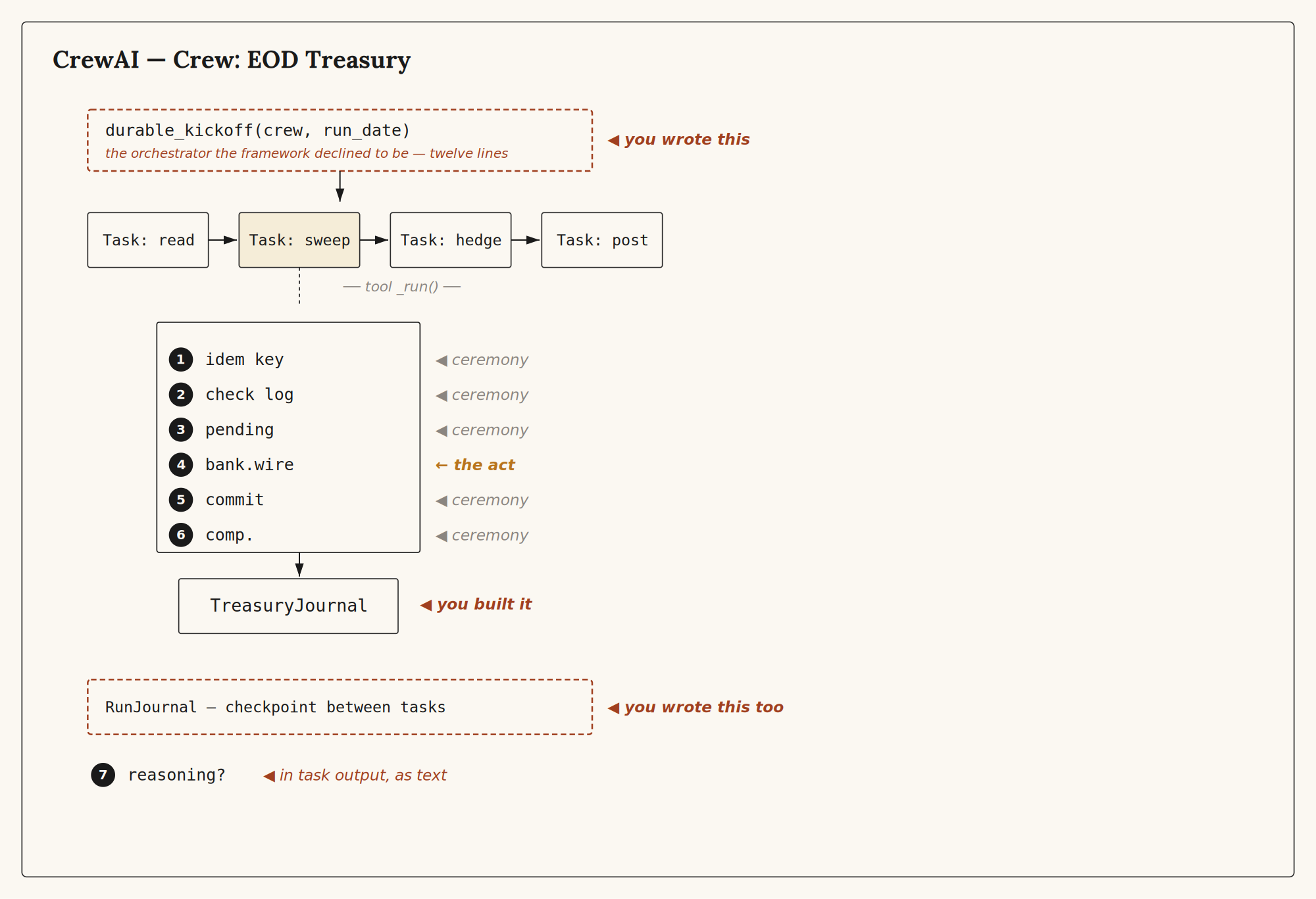
from crewai import Agent, Task, Crew
from crewai.tools import BaseTool
class ExecuteSweepTool(BaseTool):
name = "execute_sweep"
description = "Sweep excess cash to a whitelisted MMF per CFO policy."
def _run(
self, account_id: str, currency: str, amount_minor: int,
target_mmf: str, run_date: str, rationale: str,
) -> dict:
# ① idem — crew gives inputs, not invocation identity
key = hashlib.sha256(
f"{run_date}:{account_id}:{amount_minor}:{target_mmf}".encode()
).hexdigest()
# ② check
if treasury_journal.exists(key, status="confirmed"):
return {"wire_id": treasury_journal.wire_id(key)}
# ③ pending
treasury_journal.write(key, status="pending",
account_id=account_id, amount_minor=amount_minor,
target=target_mmf, rationale=rationale)
# ④ the act
try:
wire_id = bank.wire(account_id, amount_minor, target_mmf, idempotency_key=key)
except UnknownAck:
treasury_journal.write(key, status="unknown"); raise
except Exception:
treasury_journal.write(key, status="failed"); raise
# ⑤ commit
treasury_journal.write(key, status="confirmed", wire_id=wire_id)
# ⑥ compensation
compensation_journal.register(
key, kind="reverse_wire",
payload={"wire_id": wire_id, "account": account_id},
)
return {"wire_id": wire_id}
agent = Agent(role="Treasurer", goal="Close the day per CFO policy.",
tools=[ExecuteSweepTool(), ExecuteHedgeTool(), PostGLTool()])
crew = Crew(agents=[agent],
tasks=[read_task, sweep_task, hedge_task, post_task])
# Crew does not checkpoint between tasks. If `sweep` succeeds and the process
# dies before `hedge`, restart re-runs `sweep`. We write the resumption.
def durable_kickoff(crew, run_date: str):
state = run_journal.load(run_date) or {}
for i, t in enumerate(crew.tasks):
slot = f"task_{i}"
if slot in state:
continue
state[slot] = t.execute()
run_journal.save(run_date, state)
return state
8/ The kickoff wrapper is the orchestrator the framework declined to be. Twelve lines. They are the difference between a treasury that closes once and a treasury that closes twice.

What the three frameworks share⌗
9/ One scenario. Three frameworks. The same six points wired in by hand inside each tool. The same seventh point — why — captured as a string parameter and hoped to be enough.
10/ The CFO's policy is in session state in ADK, in graph state in LangGraph, in task context in CrewAI. None of those places is the journal that survives the day.
11/ The retry decorator is the tell. The compensation registration is the tell. The kickoff wrapper is the tell. Each is the developer rebuilding, badly, what the boundary already knew how to do.
12/ The treasury agent does not need a smarter model. It needs a tape underneath the model that the regulator can read.
The thread⌗
1/ The agent is not the protagonist. The protagonist is the world. The merchant's inventory. The airline's seat map. The custodian's order book. The agent is a small program negotiating commitments with larger systems that have their own opinions about what just happened.
2/ The runtime's job is to keep the agent's view of those commitments and the world's view of them in agreement across crashes, deploys, and time.
3/ Most current agent frameworks treat this as somebody else's problem. The retry decorator is the tell.
4/ Multiplied across every tool call in a multi-step agent, the developer reimplements a poor version of Temporal inside their own application, integration by integration, discovering the same edge cases in the same order the workflow community discovered them between 2014 and 2020.
III. What the Old Texts Already Say⌗
1/ Distributed systems research has spent forty years saying things that turn out to apply to agent systems with the parameters adjusted.
2/ Lamport, 1978. Time, Clocks, and the Ordering of Events. There is no global clock. Events are ordered only by their causal relationships, and that order is partial, not total.
3/ Helland. Life Beyond Distributed Transactions. ACID across services is not available. What you have are grants, agreements, and partial failures.
4/ Helland again. Memories, Guesses, and Apologies. Distributed systems live in a world of inexact information. The right primitive is often I think this is true; if I am wrong, I will apologise.
5/ Saltzer, Reed, Clark, 1984. The end-to-end argument. Reliability must be verified at the endpoints. Intermediate components cannot guarantee what the endpoint cares about.
6/ A network can promise delivery. Only the receiver can confirm it. The implication for agents is direct. The vendor's confirmation is the only commitment that counts. The agent's local belief that the order was placed is not the same thing as the order having been placed.
7/ Garcia-Molina and Salem, 1987. The saga paper. Compensation as the way to maintain weakened consistency over long-running operations. If step C fails, run ¬B and ¬A.
8/ Event sourcing. Store events. Derive state by replay. The journal becomes the source of truth.
9/ The actor model. Hewitt, Agha, Erlang/OTP. Message-driven concurrency through mailbox ordering and supervised processes that survive their own faults.
10/ Every one of these primitives assumes that the orchestrator's behaviour can be characterised at design time. Sagas have known forward graphs and known compensation graphs. Event sourcing has deterministic state transitions. Idempotency keys cover known operations. The actor model has typed messages.
11/ They were designed for a world where the orchestrator was code an engineer wrote. The engineer's job was to handle network failure within the bounds of decisions the engineer had pre-specified.
12/ This is the assumption the LLM-as-orchestrator pattern violates. The violation is structural, not incidental.
IV. The Assumption Breaks⌗
1/ The orchestrator's decisions are no longer pre-specified. They are sampled at runtime from a model whose policy was learned, not written.
2/ The difference is visible if you write the two side by side.
# Classical saga: the engineer wrote the graph at design time.
def transfer(from_acc: str, to_acc: str, amount: int) -> Receipt:
saga = Saga()
saga.add(debit, from_acc, amount, compensate=credit)
saga.add(credit, to_acc, amount, compensate=debit)
saga.add(notify, from_acc, to_acc, amount, compensate=None)
return saga.execute()
# Forward path: known. Compensation: known. Each step has a key.
# LLM-orchestrated agent: the trajectory is sampled at runtime.
async def agent(goal: str) -> State:
state = State.from_goal(goal)
while not state.done:
action = await llm.choose_action(state, available_tools) # ← runtime
result = await invoke_tool(action)
state = state.update(action, result)
return state
# Forward path: not enumerable.
# Compensation: depends on what was sampled.
# Each tool call has a key. The sequence does not.
3/ The first function is a graph. The second is a loop with a coin flip in the middle. The first can be reasoned about by induction. The second cannot.

4/ Four consequences follow.
5/ The forward path is not a graph the engineer can enumerate. It is a runtime trajectory the engineer can only constrain. Where the saga literature said here is A → B → C and here is its compensation ¬C → ¬B → ¬A, the agent literature has to say the agent will choose actions from this space at runtime, and we will have to journal what it chose so we can compensate it.
6/ The compensation depends on what the LLM did. It cannot be pre-written, because the forward path was not pre-written. Often the only thing positioned to write the compensation is the LLM itself, given the partial state and the goal.
7/ The idempotency unit is fuzzy. A single tool call is clear; the call has parameters, the parameters can be hashed, the hash is the key. An LLM-generated plan is less clear; the same prompt can produce different plans, and the plans are not naturally addressable. An agentic objective is very unclear. Book me a trip to Singapore is not a key.
8/ The verification gap widens. Classical patterns assumed there was an oracle for did the operation succeed. The bank's response said yes or no. For an agent task — did the research report answer the question well, did the support response satisfy the customer, did the coding agent fix the bug — there is no oracle. There is only a slower, more expensive judgment, often by another model, often by a human.
9/ These are not problems classical patterns solve. They are problems classical patterns assume away.

V. Six Places It Breaks⌗
A short tour. Six classes of agent. Six places the inherited toolkit runs out.
The autonomous coding agent⌗
1/ The LLM reads a ticket, plans an implementation, edits files, runs tests, iterates, opens a pull request.
2/ Classical reading: a saga. Plan, implement, test, PR. On failure, revert.
3/ The pattern breaks in three places. The plan is generated at runtime, so the saga's forward graph is not knowable when the workflow is defined. Compensation is partial: the code can be reverted, the LLM cannot. The context window has been consumed. The cost has been burned. Decisions whose value cannot be undone have been made.
4/ Replay does not reconstruct the same plan, because the plan was non-deterministic in the first place.
5/ What the system actually needs. Journaled decisions, not just side effects. The ability to fork and abandon plans cheaply. Budget enforcement. Resumption that uses the journal as memory rather than as a transcript to replay verbatim.
The browser-use agent⌗
1/ The LLM looks at a screenshot, decides where to click, types text, navigates, fills forms.
2/ Classical idempotency does not apply. Click at (453, 287) is not idempotent. The page state changes between attempts.
3/ The DOM is not a database with versioned writes. It is a stateful UI with implicit locks the LLM cannot see. Replay against the page produced two minutes later is interaction with a different page.
4/ Compensation is wildly contextual. Undo this booking is not a database revert. It is another agent run that must discover the booking, navigate to the cancellation flow, and confirm.
5/ What the system needs. Visual state snapshots in the journal. Action verification — did the click do what was intended. The ability to detect when replay has diverged from the journaled trajectory.
The SRE agent responding to a page⌗
1/ The LLM reads the alert, queries metrics, tails logs, runs probes, forms a hypothesis, applies a fix.
2/ The action space is anything you would run on a Linux box. It is unbounded. Some actions are destructive. Restart a service. Scale down a fleet. Drain a node. Compensation is partial.
3/ The system being diagnosed is changing while the agent reasons. Events that occurred while the agent was thinking are not in its context.
4/ Multiple agents on the same incident can fight. One scales up. Another scales down.
5/ Audit is not optional. Regulators and incident reviewers will ask what the agent did, why, and with what authority.
6/ What the system needs. Action-level approval gates for destructive operations. Fresh-state verification before each significant action. Multi-agent coordination via shared environment state. A journal that doubles as audit.
The customer support agent⌗
1/ The LLM reads messages, classifies intent, queries account state, decides actions, responds.
2/ The conversation accumulates commitments. I will refund $50 said in turn 2 must be honoured in turn 5. State persists across long gaps. The customer may respond two days later.
3/ Compensation logic is awkward. How do you undo an empathetic response?
4/ The LLM might commit, in language, to something the system cannot deliver. The gap between the language commitment and the system action is where the failure lives.
5/ What the system needs. Structured commitment tracking that the conversational layer renders as language but the durable layer enforces as data. Conversation suspend across days. A verification step before any commitment is rendered to the customer.
The deep-research agent⌗
1/ Open-ended question. The agent plans search queries, reads results, synthesises, follows up, builds a report.
2/ Branching is non-enumerable. What to follow up on depends on what was found.
3/ Costs accumulate. LLM calls, search calls. Without budget enforcement the agent runs to exhaustion.
4/ Citation correctness is a verification problem the system cannot easily check. Replay re-does searches and may find different results, producing a different report.
5/ What the system needs. Budget as a first-class workflow construct. Journaled provenance for every claim in the output. The recognition that replay for this class of agent means resume the search tree from where it stopped, not reproduce the same outputs.
The sales or outbound agent⌗
1/ The LLM researches a prospect, drafts an outreach, sends, follows up, books meetings.
2/ Communication is reputation-bearing. Sending the wrong message is not an idempotency problem to retry through. It is a damage event. Compensation is impossible. You cannot unsend an email.
3/ The agent's plan adapts to responses or non-responses. Pre-written drip sequences cannot adapt to the prospect's signals.
4/ Cross-agent coordination is critical. Two agents working the same prospect is a serious failure.
5/ What the system needs. Lock-and-coordinate primitives at the prospect level. Irreversible-action gates with human approval. Explicit do not contact state that lives outside any single workflow run.
The pattern across the six⌗
1/ Classical microservice primitives handle the side-effect mechanics. Idempotency on the API call. Durability on the database write. Compensation on the partial commit.
2/ They do not handle decision journaling. They do not handle action-space management. They do not handle multi-agent coordination. They do not handle fresh-state verification. They do not handle budget enforcement. They do not handle non-deterministic replay.
3/ These are the gaps the new tools are trying to fill.
VI. The Idempotent-API Defence⌗
1/ The most reasonable objection, made well, sounds like this. Stripe is idempotent on charge. The airline API is idempotent on booking. The broker is idempotent on clOrdID. A retry of the workflow re-fires the same call with the same key. The merchant dedupes. We do not need a durable runtime. We need disciplined idempotency.
2/ The objection is right and incomplete. Five specific ways. Each is best shown in code.

① Fresh UUID per attempt is not idempotency. It is a guarantee of duplication.⌗
@retry(stop=stop_after_attempt(3))
def execute_sweep(state):
key = uuid.uuid4().hex # ← regenerated every retry
bank.wire(state.account, state.amount, idempotency_key=key)
3/ The bank receives three different keys across three attempts. It dedupes none of them. The developer wrote @retry and idempotency_key= and felt safe. Both are doing the opposite of safety.
def execute_sweep(state):
key = derive(state.workflow_id, "sweep", state.step_position)
bank.wire(state.account, state.amount, idempotency_key=key)
4/ The fix needs a stable workflow identity that survives the agent's restart. The identity must come from the runtime, not from the wall clock. If the framework does not supply it, the developer has to invent it. Inventing it correctly is the job of a workflow runtime.
② Per-integration dedup does not produce workflow-level idempotency.⌗
def workflow():
bank.wire(amount, key=k1) # ✓ dedupes at the bank
# ... process dies here ...
custodian.book(amount, key=k2) # never fired
5/ On retry, the workflow has no record of having reached step one. bank.wire fires again with k1 — the bank dedupes correctly and returns the original confirmation. But the workflow does not know this happened the first time. It sees no confirmation in its own books. It may abort. It may retry from elsewhere. It may falsely report failure to the user.
6/ The journal answers this. Idempotency at the layer below the journal does not.
③ Compensation is not retry.⌗
@retry(stop=stop_after_attempt(3))
def transfer(from_acc, to_acc, amount):
debit(from_acc, amount) # succeeds
credit(to_acc, amount) # fails — counterparty closed account
# @retry replays the WHOLE function. debit fires twice (or dedupes).
# credit will never succeed. It cannot.
# The compensation — refund the debit — is never reached.
7/ When step two succeeded and step three fails, the system must run ¬2. ¬2 is a different operation than 2. Idempotent APIs help if the compensation needs to retry. They do not write the compensation. Frameworks that hand-wave compensation with use try/except are not handling it.
④ Idempotency windows are bounded.⌗
def workflow():
key = derive(...)
bank.wire(amount, key=key)
await human_approval() # ← may take 48 hours
bank.wire(remaining, key=key) # bank's key cache is 24 hours
8/ Stripe holds keys for twenty-four hours. Travel approvals, settlement cycles, multi-day human-in-the-loop flows routinely run longer. The second wire is treated as new. The dedup fails silently. The runtime must either complete the operation within the window, or detect expiry and choose a recovery strategy. That logic does not exist at the API layer.
⑤ Reasoning is not in any API contract.⌗
def execute_sweep(state):
key = derive(state)
bank.wire(state.account, state.amount, idempotency_key=key)
# The bank journal records: account, amount, key, timestamp.
# No record of WHY this account, this amount, this counterparty,
# this minute. The bank does not care.
# The auditor will.
9/ The agent decided to pick vendor A because of search snapshot X. It decided to allocate Y because of policy version Z. It decided to escalate because of error pattern W. None of this is an API call. None of it has an idempotency key. All of it is part of what makes the agent's behaviour auditable, replayable, defensible. The journal is where this lives. The API has no story for it.
10/ Idempotency at the API is necessary. It is not sufficient. The gap between necessary and sufficient is exactly the work the new tools are doing.
VII. What the New Layer Actually Does⌗
1/ Read the documentation for any current agent runtime. Temporal. Restate. DBOS. The durability features being retrofitted into LangGraph and CrewAI. What they are converging on is a layer above the classical patterns, not a replacement for them.
2/ The clearest way to see the convergence is to walk the same treasury workflow through a runtime that takes the ceremony seriously. Compare what the developer writes.

from datetime import timedelta
from temporalio import workflow, activity
@activity.defn
async def execute_sweep(sweep: SweepInput) -> str:
# ① idempotency key — derived from runtime identity, not invented
info = activity.info()
key = f"{info.workflow_id}:{info.activity_id}"
# ④ the act — and only the act
return await bank.wire(
sweep.account_id, sweep.amount_minor, sweep.target,
idempotency_key=key,
)
@workflow.defn
class TreasuryEOD:
@workflow.run
async def run(self, run_date: str, policy: Policy) -> Summary:
balances = await workflow.execute_activity(
read_balances, run_date,
schedule_to_close_timeout=timedelta(minutes=2),
)
rates = await workflow.execute_activity(
price_market, balances.currencies,
schedule_to_close_timeout=timedelta(minutes=2),
)
compensations: list[tuple] = []
try:
for sweep in policy.compute_sweeps(balances, rates):
wire_id = await workflow.execute_activity(
execute_sweep, sweep,
schedule_to_close_timeout=timedelta(minutes=5),
)
compensations.append((reverse_wire, wire_id))
for hedge in policy.compute_hedges(balances, rates):
await workflow.execute_activity(
execute_hedge, hedge,
schedule_to_close_timeout=timedelta(minutes=5),
)
await workflow.execute_activity(
post_gl, balances, rates,
schedule_to_close_timeout=timedelta(minutes=2),
)
except ActivityError:
for fn, arg in reversed(compensations):
await workflow.execute_activity(
fn, arg, schedule_to_close_timeout=timedelta(minutes=5),
)
raise
return Summary(...)
3/ Compare to the LangGraph version. What disappeared.
4/ The retry decorator. Temporal retries activities by configured policy.
5/ The idempotency key derivation. workflow_id and activity_id are supplied. The developer does not invent stability; the runtime guarantees it.
6/ The pending write before the act. The activity start is recorded in workflow history before the activity runs. History is the journal.
7/ The confirmed / failed / unknown write after the act. The activity result is recorded in history when it returns. The unknown case becomes a known runtime concept (HEARTBEAT_TIMEOUT, RETRY_POLICY) rather than a custom field in a side table.
8/ The check-the-journal lookup at the top of every tool. Replay reads from history. The agent does not re-fire confirmed activities.
9/ The kickoff resumption wrapper. Workflows resume from the last completed activity automatically.
10/ What still belongs to the developer. The idempotency key handed to the bank — Temporal supplies the stable identity, but the bank still needs a key on its API, and the developer still passes it. The compensation logic — Temporal gives saga primitives, the developer writes the compensating activities. The reasoning — the why — is still passed as an activity input or output, journaled because Temporal journals all activity inputs and outputs, but with no richer semantics than that.
11/ This is the floor closing. The exactly-once writes, the compensation paths, the idempotency at workflow scope, the long-running suspend-and-resume — these are no longer the developer's invention. They are the runtime's job.
12/ The ceiling is still being built. Reasoning provenance. Action-space gates. Multi-agent coordination through journaled state. Budget as a first-class workflow construct. Verification at consumption. Replay semantics tuned per agent class. The runtimes are converging on these. None has the full set yet.

13/ None of this is solved by Postgres plus Kafka plus a saga library. None of it is a problem Postgres plus Kafka plus a saga library was designed for. The classical toolkit handles the plumbing. What sits above the plumbing is genuinely new work.
14/ The shape of the stack, when the dust settles, looks like this.

VIII. On Substrate⌗
1/ Most of these systems are written in Python. Python is structurally hostile to most of what they require. The problems compound rather than cancel.
2/ Determinism within workflow code. Python permits non-deterministic constructs — time, random, hash randomisation, dict iteration in some contexts, threading — anywhere. Sandboxes mitigate but cannot enforce. In a world where the LLM is already a non-determinism source, having a second non-determinism source in the runtime is a recipe for replay drift.
3/ Concurrency. Python's three concurrency models — sync, asyncio, threading — compose poorly with each other and with durable execution. Most agent libraries mix all three. Workflow engines have to constrain user code to one model, fighting the language.
4/ State serialisation. pickle is fragile across Python versions and class definitions. The first deploy after a workflow goes long-running is the deploy where pickle breaks. Strongly typed alternatives like Pydantic help but are not pervasive.
5/ Hot reload. Not really possible. Long-running agents that need to be patched mid-flight are a Python anti-pattern. Erlang/BEAM was designed for this case. Python was not.
6/ Sandbox enforceability. Python's dynamism — __import__, ctypes, exec, monkey-patching — means the workflow sandbox is best-effort. Static-typed languages such as Go, Rust, and TypeScript with strict typing make the equivalent guarantees enforceable rather than documented.
7/ Process model. Python has no first-class actor model. Multi-agent systems on Python are bolted on with Ray, Dask, or custom infrastructure. None integrate with workflow journals natively.
8/ The cumulative effect. Durable agent execution tools targeting Python ship with dialect restrictions — don't use time.sleep in workflow code. Failure modes documented as developer rules rather than runtime guarantees. State-serialisation edge cases that surface at the worst possible moment.
9/ The TypeScript and Rust equivalents do not have these. The engineering economics of building durable agent execution in Python are uphill in a way that does not show up in greenfield benchmarks but compounds in production over months.
10/ The honest position. The next generation of agent infrastructure will probably not be Python at the runtime layer, even if it remains Python at the application layer. Python will write the agent. Something else will run it.
IX. The Landscape⌗
1/ The category has converged on a small set of architectural patterns implemented in different deployment models.
2/ Temporal. The most mature. Built by the team behind Cadence at Uber. Workflows written as code in Go, Java, TypeScript, Python, .NET, Ruby. Self-hosted cluster or Temporal Cloud. Production users include Snap, Netflix, HashiCorp, Box, Datadog, JPMorgan Chase. Agent integrations announced across the OpenAI Agents SDK and the Vercel AI SDK in 2025. Strong on long-running workflows. Heavier operational footprint.
3/ Restate. Newer, from former Apache Flink and Meta engineers. Single-binary Rust runtime. Optimised for low-latency durable execution and serverless or edge deployment. Strong agent positioning. Production users include 21Bitcoin for trade orchestration, Coralogix for agentic observability fleets, Deliveru for recruiting research agents. Lighter than Temporal. More opinionated about deployment.
4/ DBOS. The simplest operational model. Durable execution as an in-process library backed by Postgres. No new infrastructure beyond your existing database. Fits teams that already have Postgres at the centre and do not want a new clustered service.
5/ Cloud-provider-native. AWS Step Functions. Azure Durable Functions. Cloudflare Workflows. Step Functions is the oldest and predates the modern category. Cloudflare brought step-based durable execution to the edge in 2025, with multi-day execution and Python support.
6/ Hosted lightweight. Inngest. Hatchet. TypeScript- and Python-first. Targeting application teams that want durable execution without standing up Temporal. Lighter integration. Narrower scope. Simpler deployment.
7/ The agent framework category. LangGraph, CrewAI, ADK. A different layer. Graph runtimes or orchestration libraries with bolted-on durability. LangGraph's checkpointers are the most mature of the bolt-ons. The granularity is at node boundaries rather than effect boundaries. The patterns are documented as user discipline rather than runtime guarantees.
8/ The realistic move for any team building an agent system that needs the properties this essay has been describing. Put a durable execution engine underneath the agent framework. Do not rely on the framework's own durability features.
9/ The integrations announced in 2025 across Temporal, Restate, and the major agent SDKs reflect this. The agent framework community is ceding the runtime layer to the durable execution category and focusing on the composition layer above it.
10/ The honest read of the landscape. The runtime layer is being built. The agent framework layer is, increasingly, an application of it.
X. Floor and Ceiling⌗

1/ The deflationary argument — we already have sagas — is correct for the I/O layer and incomplete for everything above it.
2/ The exactly-once writes. The compensation. The idempotency. The long-running workflow primitives that Garcia-Molina and Salem named in 1987 and that two decades of microservice engineering refined into something operational. That is the floor. It is solved.
3/ Anyone building an agent that ignores the floor will discover the same edge cases in the same order the workflow community discovered them between 2014 and 2020.
4/ Decision journaling. Adaptive compensation. Action-space management. Multi-agent coordination. Fresh-state verification. Budget enforcement. Replay semantics tuned per agent class. That is the ceiling. It is being built.
5/ The saga literature does not solve it because the saga literature did not need to. The saga literature assumed the orchestrator was code. When the orchestrator is an LLM, the assumption no longer holds, and the work above the floor is genuinely new.
6/ The people who say we already have sagas are right that the floor is solved. The people who say we need new tools are right that the ceiling is not. Both are talking past each other because the language has not separated the two.
7/ The agent durable execution category, when it survives the marketing layer, is the ceiling.
8/ The chatbot was forgiven for forgetting. The agent will not be. An agent is a contract with the world. The runtime is what keeps the contract honest.